题目 将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:
graph LR
a((1)) --> b((2)) --> c((4))
graph LR
d[1] --> e[3] --> f[4]
graph LR
a((1)) --> d[1] --> b((2)) --> e[3] --> c((4)) --> f[4]
输入:l1 = [1,2,4], l2 = [1,3,4]
示例 2:
示例 3:
提示:
题解 很简单,定义第三个链表,然后依次比较两个有序链表的每一位,小的先接到第三个链表后面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public : ListNode* mergeTwoLists (ListNode* l1, ListNode* l2) { ListNode* dummyNode = new ListNode (0 ); ListNode* pre = dummyNode; while (l1 != NULL && l2 != NULL ) { if (l1->val <= l2->val) { pre->next = l1; l1 = l1->next; } else { pre->next = l2; l2 = l2->next; } pre = pre->next; } if (l1 == NULL ) { pre->next = l2; } else if (l2 == NULL ) { pre->next = l1; } return dummyNode->next; } };
题目 给你一个链表数组,每个链表都已经按升序排列。
示例 1:
示例 2:
示例 3:
提示:
题解1 根据之前的合并两个有序链表 ,遍历链表组中的元素,两两合并即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public : ListNode* mergeTwoLists (ListNode* l1, ListNode* l2) { ListNode* dummyNode = new ListNode (0 ); ListNode* pre = dummyNode; while (l1 != NULL && l2 != NULL ) { if (l1->val <= l2->val) { pre->next = l1; l1 = l1->next; } else { pre->next = l2; l2 = l2->next; } pre = pre->next; } if (l1 == NULL ) { pre->next = l2; } else if (l2 == NULL ) { pre->next = l1; } return dummyNode->next; } ListNode* mergeKLists (const vector<ListNode*>& lists) { if (lists.size () == 0 ) { return NULL ; } ListNode* result = NULL ; for (int i = 0 ; i < lists.size (); i++) { result = mergeTwoLists (result, lists[i]); } return result; } };
题解2 题解1是按顺序合并,每次合并完的链表就会加长,下一次合并又得遍历一遍,所以时间复杂度会高。lists=[[1, 2], [3, 4], [5, 6], [7, 8]],首先拆分成[[1, 2], [3, 4]]和[[5, 6], [7, 8]],然后两组分别组内合并,得到两个链表,再互相合并。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 class Solution { public : ListNode* mergeTwoLists (ListNode* l1, ListNode* l2) { ListNode* dummyNode = new ListNode (0 ); ListNode* pre = dummyNode; while (l1 != NULL && l2 != NULL ) { if (l1->val <= l2->val) { pre->next = l1; l1 = l1->next; } else { pre->next = l2; l2 = l2->next; } pre = pre->next; } if (l1 == NULL ) { pre->next = l2; } else if (l2 == NULL ) { pre->next = l1; } return dummyNode->next; } ListNode* merge (const vector<ListNode*>& lists, int left, int right) { if (left == right) { return lists[left]; } if (left > right) { return NULL ; } int mid = (left + right) >> 1 ; ListNode* l1 = merge (lists, left, mid); ListNode* l2 = merge (lists, mid + 1 , right); return mergeTwoLists (l1, l2); } ListNode* mergeKLists (const vector<ListNode*>& lists) { if (lists.size () == 0 ) { return NULL ; } return merge (lists, 0 , lists.size () - 1 ); } };
题解3 因为最后返回的链表中数组是按由小到大排序的,而C++自带的优先队列priority_queue,可以自动帮我们排序。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution { public : ListNode* mergeKLists (vector<ListNode*>& lists) { ListNode* res = new ListNode (); priority_queue<int , vector<int >, greater<int >> queue; for (auto list : lists) { while (list != NULL ) { queue.push (list->val); list = list->next; } } ListNode* temp = res; while (!queue.empty ()) { ListNode* node = new ListNode (); node->val = queue.top (); queue.pop (); temp->next = node; temp = temp->next; } return res->next; } };
题解4 题解3用的是C++自带的priority_queue,我们也可以自己定义类似的queue,从小到大排序。
1 2 3 4 5 struct Status { int val; ListNode* ptr; bool operator <(const Status& rhs) const { return val > rhs.val; } };
其余的和题解3类似。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution { public : ListNode* mergeKLists (vector<ListNode*>& lists) { struct Status { int val; ListNode* ptr; bool operator <(const Status& rhs) const { return val > rhs.val; } }; ListNode* res = new ListNode (); priority_queue<Status> queue; for (auto list : lists) { while (list != NULL ) { queue.push ({list->val, list}); list = list->next; } } ListNode* temp = res; while (!queue.empty ()) { ListNode* node = new ListNode (); node->val = queue.top ().val; queue.pop (); temp->next = node; temp = temp->next; } return res->next; } };
题目 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
graph LR
a1 --> a2 --> c1
b1 --> b2 --> b3 --> c1 --> c2 --> c3
题目数据 保证 整个链式结构中不存在环。
intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
listA - 第一个链表
listB - 第二个链表
skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
graph LR
a[4] --> b[1] --> 8
d[5] --> 6 --> e[1] --> 8 --> f[4] --> g[5]
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
示例 2:
graph LR
a[1] --> 9 --> b[1] --> 2
3 --> 2 --> 4
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
示例 3:
graph LR
2 --> 6 --> 4
1 --> 5
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
提示:
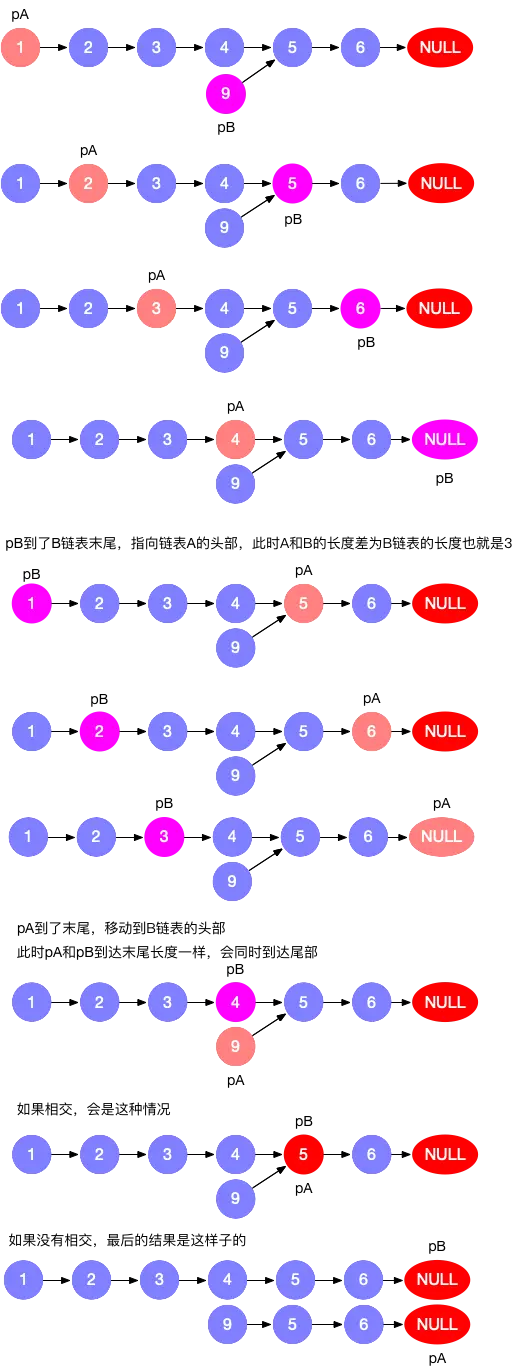
题解 直接看图更好理解,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public : ListNode* getIntersectionNode (ListNode* headA, ListNode* headB) { if (headA == NULL || headB == NULL ) { return NULL ; } ListNode *pA = headA, pB = headB; while (pA != pB) { pA = (pA == NULL ) ? headB : pA->next; pB = (pB == NULL ) ? headA : pB->next; } return pA; } };
题目 给定一个单链表 L 的头节点 head ,单链表 L 表示为:
示例 1:
示例 2:
提示:
题解 这题其实是个大杂烩,寻找链表中点(快慢指针) + 链表逆序(反转链表) + 合并链表,这三个的合集。
举个例子,链表 1 -> 2 -> 3 -> 4 -> 5 -> 6
第一步找中点的话,很明显用快慢指针。快指针一次走两步,慢指针一次走一步,当快指针走到终点的话,慢指针会刚好到中点。如果节点个数是偶数的话,slow 走到的是左端点,利用这一点,我们可以把奇数和偶数的情况合并,不需要分开考虑。(快慢指针参考环形链表问题 )
第二步链表逆序的话,有迭代和递归的两种方式,迭代的话主要利用两个指针,依次逆转。(反转链表参考反转链表问题 )
第三步的话就很简单了,两个指针分别向后移动就可以。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 class Solution { public : void reorderList (ListNode* head) if (head == NULL || head->next == NULL ) return ; ListNode* slow = head; ListNode* fast = head; while (fast->next && fast->next->next) { slow = slow->next; fast = fast->next->next; } ListNode* reverseNode = slow->next; slow->next = NULL ; reverseNode = reverseList (reverseNode); while (reverseNode) { ListNode* tempHead = head->next; ListNode* tempReverse = reverseNode->next; head->next = reverseNode; reverseNode->next = tempHead; head = tempHead; reverseNode = tempReverse; } } ListNode* reverseList (ListNode* head) { ListNode* next = NULL ; ListNode* prev = NULL ; while (head) { next = head->next; head->next = prev; prev = head; head = next; } return prev; } };
题目 给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:
graph LR
4 --> 2 --> 1 --> 3
—>
graph LR
1 --> 2 --> 3 --> 4
输入:head = [4,2,1,3]
示例 2:
graph LR
-1 --> 5 --> 3 --> 4 --> 0
—>
graph LR
-1 --> 0 --> 3 --> 4 --> 5
输入:head = [-1,5,3,4,0]
示例 3:
提示:
题解1 要实现排序算法 可以知道,符合要求的只有快速排序和归并排序。
首先是快速排序,回顾数组的快排步骤:
那么链表也可以同样的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 class Solution { public : ListNode* sortList (ListNode* head) { if (!head || !head->next) { return head; } ListNode *left = new ListNode (0 ), *right = new ListNode (0 ), *mid = new ListNode (0 ); ListNode *i = left, *j = right, *m = mid; int pivot = getMid (head)->val; ListNode* cur = head; while (cur) { if (cur->val < pivot) { i->next = cur; i = i->next; } else if (cur->val > pivot) { j->next = cur; j = j->next; } else { m->next = cur; m = m->next; } cur = cur->next; } i->next = j->next = m->next = NULL ; left->next = sortList (left->next); right->next = sortList (right->next); cur = left; while (cur->next) { cur = cur->next; } cur->next = mid->next; while (cur->next) { cur = cur->next; } cur->next = right->next; return left->next; } ListNode* getMid (ListNode* head) { ListNode* fast = head; ListNode* slow = head; while (fast != nullptr && fast->next != nullptr ) { fast = fast->next->next; slow = slow->next; } return slow; } };
题解2 上面说了,归并也可以解决这道题。
那么链表也可以同样的操作:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Solution { public : ListNode* sortList (ListNode* head) { if (!head || !head->next) return head; ListNode *slow = head, *fast = head; while (fast->next && fast->next->next) { slow = slow->next; fast = fast->next->next; } fast = slow->next; slow->next = NULL ; return merge (sortList (head), sortList (fast)); } ListNode* merge (ListNode* l1, ListNode* l2) { ListNode *dummy = new ListNode (0 ), *cur = dummy; while (l1 && l2) { if (l1->val < l2->val) { cur->next = l1; l1 = l1->next; } else { cur->next = l2; l2 = l2->next; } cur = cur->next; } cur->next = l1 ? l1 : l2; return dummy->next; } };
题目 给定一个已排序的链表的头 head , 删除所有重复的元素,使每个元素只出现一次 。返回 已排序的链表 。
示例 1:
graph LR
a(1) --> b(1) --> c(2)
—>
graph LR
a(1) --> b(2)
输入:head = [1,1,2]
示例 2:
graph LR
a(1) --> b(1) --> c(2) --> d(3) --> e(3)
—>
graph LR
a(1) --> b(2) --> c(3)
输入:head = [1,1,2,3,3]
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序 排列
题解 1、首先,使用虚拟头结点dummyNode,让它的next指针指向head,这样可以避免对head进行特判;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution { public : ListNode* deleteDuplicates (ListNode* head) { ListNode* dummyNode = new ListNode (0 ); dummyNode->next = head; while (head) { while (head->next && head->val == head->next->val) { head->next = head->next->next; } head = head->next; } return dummyNode->next; } };
题目 给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
graph LR
a(1) --> b(2) --> c(3) --> d(3) --> e(4) --> f(4) --> g(5)
—>
graph LR
a(1) --> b(2) --> c(5)
输入:head = [1,2,3,3,4,4,5]
示例 2:
graph LR
a(1) --> b(1) --> c(1) --> d(2) --> e(3)
—>
graph LR
a(2) --> b(3)
输入:head = [1,1,1,2,3]
提示:
题解 跟上面第六题类似,只不过这里所有重复的都删除,不保留。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution { public : ListNode* deleteDuplicates (ListNode* head) { ListNode* dummyNode = new ListNode (0 ); dummyNode->next = head; ListNode* pre = dummyNode; while (head) { bool flag = false ; while (head->next && head->val == head->next->val) { head = head->next; flag = true ; } if (flag) { pre->next = head->next; } else { pre = head; } head = head->next; } return dummyNode->next; } };